
Data processing systems are now the foundation of modern digital platforms. They combine data from multiple sources, process it continuously, and deliver reliable results that drive business decisions, ranking algorithms, and analytical models.
To ensure such systems are scalable, efficient, and resilient, they must be properly tested – not only at the backend level, but across the entire data processing pipeline.
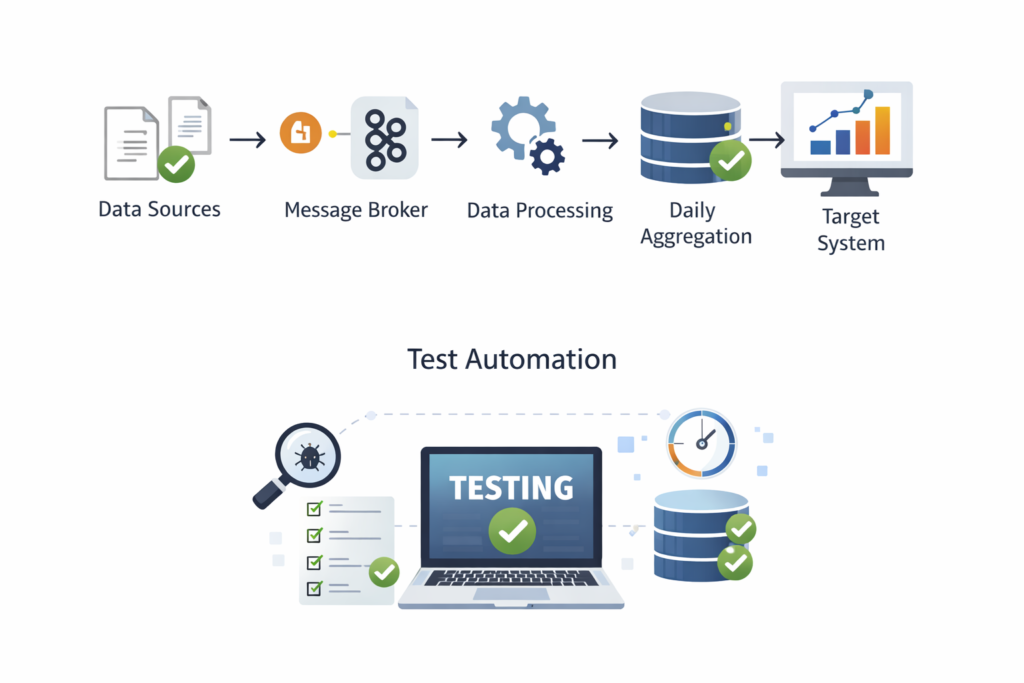
In this article, we present a practical approach to testing data processing systems, based on real project experience in an event-driven architecture using message brokers and daily aggregations.
What is a data processing system?
A data processing system is a solution that:
- collects data from one or multiple sources,
- cleans and normalizes the data,
- processes it according to defined algorithms,
- aggregates results,
- stores outcomes and exposes them to downstream systems.
What makes such systems unique is that the process is continuous and cyclical. Data is not delivered once – new events are constantly ingested, processed, and recalculated.
Why is data processing testing so important?
At first glance, data processing tests may look like standard backend tests. However, practical experience quickly shows that:
- we are not only testing APIs or business logic,
- we are testing data flow, transformations, aggregations, and time-based consistency.
In systems handling large data volumes and asynchronous processing, insufficient testing often leads to:
- incorrect results,
- duplicated data,
- inconsistent aggregates,
- performance bottlenecks.
Goals of data processing system tests
Testing data processing systems serves several key objectives:
- Algorithm correctness
Verifying that processed data matches business expectations. - Performance and response time
Evaluating how the system behaves under high event throughput. - Scalability
Ensuring the system handles increasing data volume and additional sources. - Data consistency
Confirming that data from different sources is merged correctly. - Fault tolerance
Making sure invalid input data does not break the entire pipeline.
What can be tested?
In data processing testing, the scope goes beyond a single component. Test subjects may include:
- individual processing functions,
- entire microservices,
- aggregation procedures,
- system integrations,
- full end-to-end data pipelines.
How to test data processing systems?
Unit, integration and system tests
Effective testing combines multiple test layers:
- unit tests – verifying individual transformations,
- integration tests – validating communication between components,
- system tests – covering the entire data processing flow,
- end-to-end tests – ensuring data travels correctly from source to target.
Test Automation
Automation is essential because it allows teams to:
- validate large data sets,
- repeat scenarios deterministically,
- detect regressions early.
This is especially important in event-driven systems using message brokers.
Example data processing architecture
In the described project, data:
- arrived as events via message brokers (Kafka, RabbitMQ),
- was converted from JSON into Avro format,
- passed through aggregation layers,
- was stored as daily data aggregates,
- fed analytical and ranking systems.
This architecture enabled:
- flexible data processing,
- multiple consumers,
- clear separation of responsibilities between services.
Preparing test data
The first step was defining input data:
- from one or multiple sources,
- represented as JSON or simple text structures,
- prepared as templates with dynamic fields.
This approach allowed fast generation of test scenarios without building complex objects in code.
Sending and reading data in tests
Tests primarily used:
- Kafka and RabbitMQ for sending events,
- Kafka and REST APIs for reading processed data.
Verification focused on:
- whether data appeared at all,
- whether it was transformed correctly,
- whether it complied with schemas (e.g. Avro),
- whether duplicates were eliminated.
Verifying processed data
Each processing stage was validated independently:
- correctness of individual records,
- aggregation per source,
- aggregation per entity (e.g. shipper),
- daily aggregation logic,
- merging data from multiple sources.
Special attention was paid to duplicate elimination, one of the most common issues in event-driven systems.
System resilience to invalid data
One key lesson learned was that: incorrectly prepared test data must never stop the entire processing pipeline.
Systems should be resilient to:
- schema mismatches,
- partially invalid events,
- unexpected values.
This requires both proper safeguards in system design and disciplined testing practices.
Testing daily aggregations and historical data
Daily aggregates were critical for downstream logic:
- data was summed per day,
- records from different sources were merged,
- historical data (e.g. 30, 60, or 365 days) powered ranking algorithms.
Tests validated that:
- aggregates were calculated correctly,
- dates were assigned properly,
- current-day and historical data were clearly distinguished.
Testing algorithms based on processed data
At the end of the pipeline, processed data fed ranking algorithms where:
- composite indicators were calculated,
- historical context mattered,
- single events could significantly affect final scores.
These tests required carefully prepared datasets so that expected values could be asserted precisely.
End-to-end tests – the final step
End-to-end tests were executed at the final stage to:
- validate the full data flow,
- confirm that events published to the message broker reached the target system,
- cover basic happy path scenarios only.
Their purpose was not deep logic validation, but ensuring the entire ecosystem worked together.
Key takeaways: data processing tests are more than backend tests
The most important conclusion is simple:
data processing testing is a separate testing discipline that requires:
- understanding the full data flow,
- awareness of how single events affect aggregates,
- a deliberate testing strategy,
- automation and isolation of individual pipeline stages.
This approach enables teams to build data systems that are resilient, scalable, and ready for real-world production workloads.


