
Większość artykułów o przeglądzie kodu generowanego przez AI zaczyna się od checklisty. Ten zaczyna się wcześniej. Od pytania, które każda checklista przemilcza: czy w ogóle powinieneś czytać ten kod?
Wiem, co teraz myślisz. Ale zanim odpiszesz „oczywiście” wyobraź sobie typowy wtorek w zespole z wysoką adopcją AI. Cursor generuje PR. Potem drugi. Potem jeszcze trzy, bo ktoś puścił agenta na backlogu. Do południa masz w kolejce więcej diffów niż przez ostatni tydzień. Recenzenci (ci sami ludzie co rok temu, z tą samą liczbą godzin) zaczynają przeglądać zamiast czytać.
Dane to potwierdzają brutalnie: przy intensywnym użyciu AI liczba scalanych PR-ów rośnie o 98%, ale czas review o 91%. Doświadczeni inżynierowie potrzebują średnio 4,3 minuty na jedną sugestię AI. Przy kodzie ludzkim to 1,2 minuty.
A czas ucieka.
Dlaczego stary model nie pasuje do nowego kształtu pracy
Code review w obecnej formie upowszechniło się dopiero około 2012–2014. Było odpowiedzią na konkretny problem: ludzie piszący kod potrzebowali świeżego spojrzenia innego człowieka, który rozumie kontekst i potrafi wychwycić błędy logiczne. Ten model miał jedno ukryte założenie: kod jest czytany przez kogoś, kto go rozumie. Linia po linii, z pełną znajomością systemu.
Agent generuje 500 linii w kwadrans. Recenzent dostaje diff wielkości sprintu i jeśli jest uczciwy wobec siebie przegląda, nie czyta. Niektórzy próbują to rozwiązać sprytnie: puszczają kod przez inny model. Świeże oczy, tyle że mechaniczne. Problem w tym, że oba modele mają te same ślepe plamy tylko żaden z nich o tym nie wie.
Co więcej, kod AI generuje 1,7x więcej problemów niż kod ludzki, a prawie połowa developerów mówi, że debugowanie kodu napisanego przez AI zajmuje im więcej czasu, niż naprawianie kodu pisanego przez ludzi. Zmęczenie recenzentów jest realne. Im więcej kodu wpada do kolejki, tym więcej rzeczy prześlizguje się przez siatkę.
Czy powinieneś przeglądać kod generowany przez AI? Tak, ale nie tak, jak myślisz
Zamiast pytać „czy ten kod jest napisany poprawnie?” warto pytać „czy dobrze zdefiniowaliśmy problem, który ten kod ma rozwiązać?”
Checkpoint człowieka ma sens. Tyle że ustawiamy go za późno. Zanim agent napisze pierwszą linię, ktoś w zespole powinien już wiedzieć: co dokładnie ma powstać, jakie są ograniczenia i po czym poznamy że to działa. Specyfikacja, kryteria akceptacji, kontrakty domenowe – to jest robota dla człowieka. Kod to tylko skutek tych decyzji.
Nie wymyślamy koła na nowo. Kiedyś punkt kontrolny stał na samym końcu. Waterfall, wielkie zatwierdzenie, dopiero potem produkcja. Przesunęliśmy go do środka i nazwaliśmy CI. Możemy przesunąć go jeszcze raz.
Tradycyjny review vs. spec-driven approach: co się zmienia
| Tradycyjny code review | Spec-driven approach | |
| Gdzie jest human checkpoint | Po napisaniu kodu (diff review) | Przed napisaniem kodu (spec, AC) |
| Co człowiek zatwierdza | Implementację – linia po linii | Intencję – kryteria akceptacji, kontrakty |
| Co weryfikuje błędy | Reviewer (człowiek lub AI) | Deterministyczne testy, lintery, SAST |
| Skalowalność | Nie skaluje się przy 10x więcej PR-ów | Skaluje się – guardrails działają automatycznie |
| Gdzie leży ryzyko | Reviewer fatigue, pominięte błędy | Źle zdefiniowana specyfikacja |
| Kiedy wymagane human review | Zawsze, na każdym PR | Przy krytycznych domenach: auth, płatności, schemat DB |
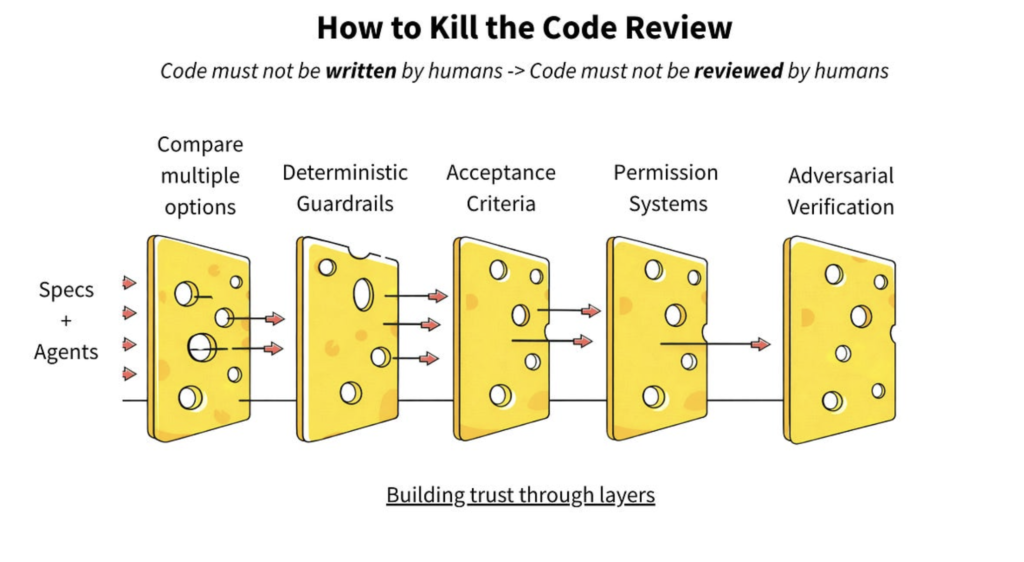
Pięć warstw, które zastępują tradycyjny review
Jeśli nie możemy przeczytać całego kodu, a przy obecnym tempie produkcji nie możemy, potrzebujemy systemu warstw, w którym żadna pojedyncza dziura nie powoduje awarii na produkcji. Model Zamiast prosić jednego agenta, żeby „napisał dobrze”, poproś trzech, żeby napisali inaczej, i wybierz najlepszy wynik. Niech rywalizują. Koszt tej opcjonalności jest dziś najniższy w historii inżynierii oprogramowania.
Selekcja nie musi być ręczna. Można rankingować wyjścia według tego, który diff jest najmniejszy, który przechodzi najwięcej testów, który nie wprowadza nowych zależności. Konkurencja daje sygnał, którego nie dostaniesz z jednej próby.
Warstwa 2: Deterministyczne zabezpieczenia
Tu nie chodzi o opinie a o fakty. Testy, sprawdzanie typów, weryfikacja kontraktów. Agent nie negocjuje z failing testem. Albo spełnia specyfikację, albo nie.
Zabezpieczenia warto ułożyć w hierarchię:
- Coding guidelines – custom lintery egzekwujące styl i konwencje
- Organizacyjne invarianty – absolutne zakazy, np. „żadnych hardcoded credentials”
- Domain contracts – reguły specyficzne dla serwisu, np. „w domenie płatności wszystkie kwoty używają typu Money”
- Acceptance criteria – kryteria specyficzne dla danego zadania
Kluczowe zastrzeżenie: kryteria weryfikacji muszą powstawać przed kodem, nie po. Jeśli agent pisze i kod, i testy do niego to problem jest tylko przesunięty, nie rozwiązany. Weryfikacja musi pochodzić ze specyfikacji, nie z implementacji. Dobrze zaprojektowany pipeline testów automatycznych jest w tym modelu pierwszą i najważniejszą linią obrony, nie ostatnią.
Warstwa 3: Ludzie definiują, co znaczy sukces
Behavior-Driven Development nie przyjął się szerzej, bo pisanie specyfikacji przed kodem wydawało się dodatkową pracą. Przy agentach równanie się odwraca: specyfikacja nie jest kosztem narzutu, to jest właściwa praca.
Człowiek pisze: „użytkownik z rolą admin może usunąć konto, użytkownik z rolą viewer nie może”. Agent implementuje. Framework BDD weryfikuje. Nikt nie musi czytać implementacji, dopóki coś nie zawiedzie. Tu ludzki osąd jest najcenniejszy: definiowanie tego, co „poprawne” znaczy, z uwzględnieniem logiki biznesowej, przypadków brzegowych i tego, co może pójść nie tak. Agent tłumaczy intencję na kod. Specyfikacja BDD staje się warstwą weryfikacji – deterministyczną, zautomatyzowaną i istniejącą przed pierwszą linią kodu.
Warstwa 4: Uprawnienia jako architektura
Co ten agent może dotknąć? Co wymaga eskalacji? To są decyzje architektoniczne, nie opcje konfiguracyjne.
Agent naprawiający bug w utils/dates.py nie potrzebuje dostępu do całego repozytorium. Dostaje dostęp do tego pliku i jego testu. Zakres powinien być tak wąski, jak to możliwe przy zachowaniu użyteczności.
Wyzwalacze eskalacji są równie ważne: dotknięcie logiki autoryzacji, modyfikacja schematu bazy, dodanie nowej zależności – to powinno automatycznie flagować do ludzkiego review, niezależnie od poziomu pewności siebie agenta.
Warstwa 5: Weryfikacja przez konfrontację
Jeden agent pisze kod. Drugi (który nie wie, co tamten zrobił) próbuje go złamać. Nie ufają sobie nawzajem. I o to dokładnie chodzi. To stary wzorzec przeniesiony na nowy grunt: QA nie powinno raportować do engineering managera, a osoba, która napisała kod, nie powinna być jedyną, która go przejrzała.
Przy agentach można to wyegzekwować architektonicznie – coding agent nie wie, czego szuka verification agent, a verification agent nie może modyfikować kodu, żeby ułatwić sobie robotę. Trzeci agent może aktywnie szukać przypadków brzegowych i failure mode’ów – red team/blue team, automatyczny, uruchamiany na każdej zmianie. W praktyce to rozszerzenie tego, co tradycyjnie robią usługi testowania, tyle że działające w pętli bez udziału człowieka na każdej iteracji.
Co warto zachować z tradycyjnego podejścia?
Żeby nie było wątpliwości pewne elementy klasycznego review nadal mają sens. Konkretnie te, których nie da się zautomatyzować.
Decyzje architektoniczne. Czy ta implementacja będzie utrzymywalna za rok? Czy wprowadza ukryte zależności, które okażą się problemem przy skalowaniu? Agent optymalizuje pod kątem zadania. Nie rozumie historii decyzji ani kierunku, w którym zmierza system. To jeden z powodów, dla których tworzenie oprogramowania na zamówienie opartego na AI wciąż wymaga seniorskiego nadzoru architektonicznego, ponieważ zmieniły się narzędzia ale nie odpowiedzialność.
Logika biznesowa z niuansami. Przypadki brzegowe, które nie wynikają z kodu, tylko z wiedzy o domenie. Rzeczy, które technicznie działają, ale są semantycznie błędne w kontekście produktu.
Bezpieczeństwo w krytycznych miejscach. Logika autoryzacji, obsługa płatności, przetwarzanie danych osobowych – tu review ludzkie ma sens niezależnie od warstw automatycznych. Nie dlatego że agent na pewno popełni błąd, ale dlatego że koszt błędu jest za wysoki. Różnica jest subtelna, niemniej ważna: nie rezygnujesz z ludzkiego osądu jedynie przenosisz go tam, gdzie jest niezastąpiony.
Pytania kontrolne dla Twojego zespołu
Jeśli Twój zespół aktywnie korzysta z AI do pisania kodu, oto zestaw pytań wart przeglądu:
Gdzie jest Twój human checkpoint? Czy zatwierdzasz specyfikacje i kryteria akceptacji, czy tylko przeglądasz diffy? Jeśli to drugie to checkpoint jest w złym miejscu.
Czy Twoje zabezpieczenia są deterministyczne? Linter, testy, sprawdzanie typów, SAST. Ile z nich uruchamia się automatycznie w CI/CD, zanim jakikolwiek człowiek patrzy na kod?
Kto pisze acceptance criteria? Jeśli agent pisze i kod, i testy to masz problem z warstwą weryfikacji. Kryteria muszą pochodzić ze specyfikacji, nie z implementacji.
Jak wąskie są uprawnienia Twoich agentów? „Dostęp do całego repo” to nie jest domyślna, właściwa odpowiedź.
Co monitorujesz po deploymencie? Feature flags, instant rollback, observability – to ostatnia warstwa bezpieczeństwa. Przyspieszenie bez guardrails zwiększa ryzyko: AI-generated code jest bardziej zmienny i bardziej podatny na poważne problemy bez odpowiednich zabezpieczeń w miejscu.
Podsumowanie
Reviewing AI-generated code nie znika. Powinniśmy jednak zmienić, co i kiedy recenzujemy.
Tradycyjny przegląd linia po linii traci sens przy skali, którą generuje AI. A wydawanie na to seniorskiej uwagi zaczyna być zwyczajnie nieracjonalne, skoro tę samą robotę może zrobić failing test.
Najszybsze zespoły, które znam, nie ufają AI bardziej niż inne. Zbudowały lepsze siatki bezpieczeństwa i dzięki temu mogą sobie pozwolić na to, żeby nie czytać każdej linii. Ludzki osąd zostawiają na rzeczy, których żaden model nie ogarnie: decyzje architektoniczne, logikę biznesową z historią, miejsca gdzie technicznie działa, to za mało.
Przyszłość to: wdrażaj szybko, monitoruj wszystko, wycofuj jeszcze szybciej.
Nie: przeglądaj wolno, przegap błędy i tak, diagnozuj na produkcji.


