
In today’s world data is king, and you need to have a clear view of its entirety if you want to make proper use of it. In this article, we’ll show you how to use widely available free tools to create a platform for streaming data from multiple sources to a single source – for static or real-time analysis.
Mind that we won’t delve too deeply into Apache Kafka itself, since this subject is too vast for one post. Instead, we’ll present a classic and practical example used by companies that migrated to microservices.
Here’s an example of how you can use data streams
Let’s assume you have a service or an app based on microservices. They’re represented by the white blocks in the picture below. So an analyst comes in and asks you for data from one of the microservices, and now you have to hand it to him somehow. The easy way would be to take a snapshot and forward it to the guy. Here it is, enjoy, all the best!
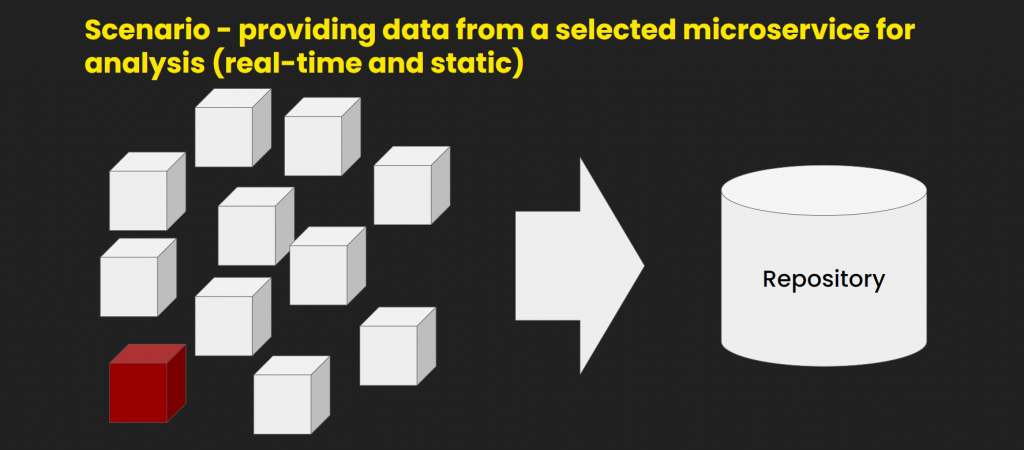
But it’s never that easy. He also needs real-time data. In most cases, this won’t be too big of a problem. If you implemented event-sourcing, meaning that your microservices emit events, you can just gather them all and save in a repository.
But whelp, that annoying guy wants the data from the red block, a microservice so old that no one touched it in ages. It does work, but we really don’t want to interfere with it, because for the one to do so it would probably open a Pandora’s box.
Let’s take a look then, and carefully, at what we are dealing with. We have a service that uses a MySQL database and we really don’t want to touch either.
So, we want to extract the data, but without really changing anything in the database. What would help is a data stream to perform real-time analysis on. But what does that mean? Precisely that we want to receive and stream data about the current state of the database, but also about all the changes it undergoes. If any record is updated, deleted, or edited, we want to get a notification. We want to stream this data to the repository – in our case, to the AWS S3 repository.
What’s S3? It’s a simple storage service repository from Amazon. However, for analysts, S3 is a great storage because it’s possible to perform SQL queries directly on files stored in S3 with AWS Athena and use the data as input for Amazon EMR engines.
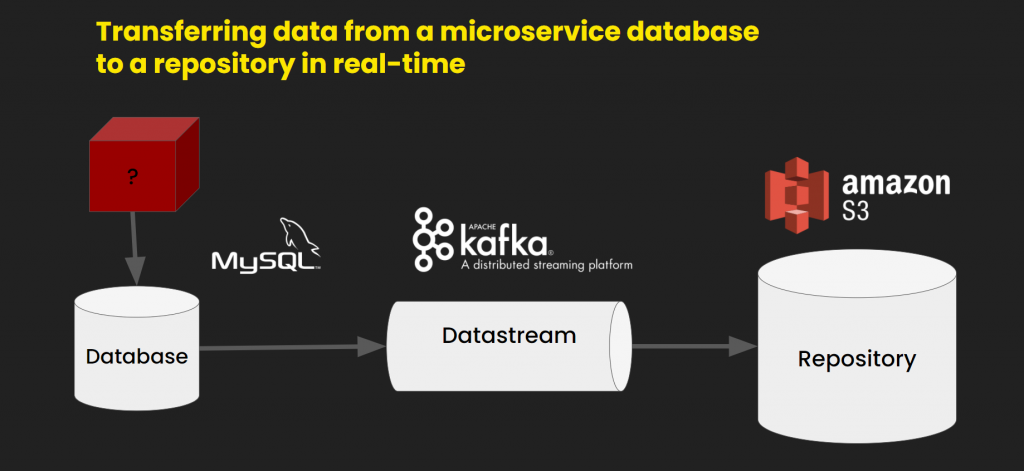
First, we have to pick a broker – a medium which we’ll use for data transfers. We chose Kafka due to its scalability and incredible performance, up to millions of events per second. It also supports clusters, it’s highly accessible and fault-tolerant. Kafka also features a KSQL module that allows placing queries for any time frame in the data stream.
Read more about Kafka >>
Extracting data with Change Data Capture (CDC)
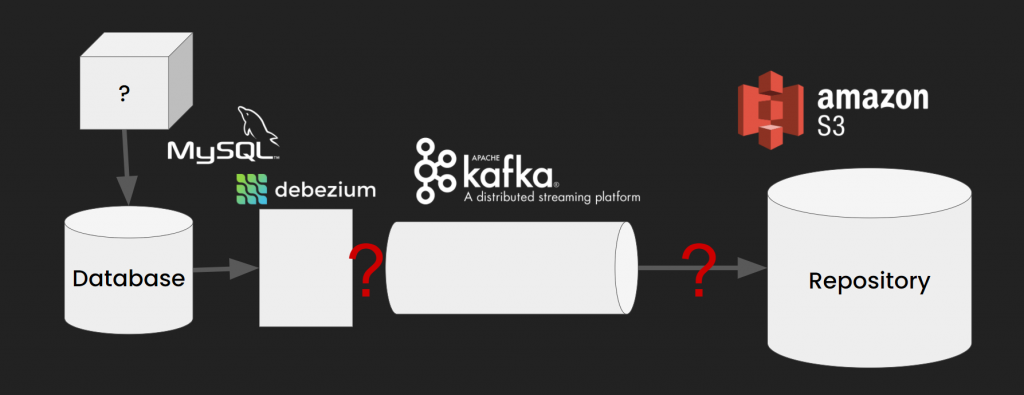
There are many ways to get the data you need, but log-based CDC is what interests us the most.
This method uses a transaction log that chronicles every event in the database in a form similar to one’s used in brokers, which is ideal for our case. This allows us to resend the whole database through Kafka fast, leaving the database intact.
We don’t really 'touch’ the database at all! This is what we meant at the beginning, so we will use this method.
To use log-based CDC we need Debezium, an open-source tool that allows us to track the changes in the database. Debezium supports MongoDB, MySQL, PostgreSQL, SQL Server, Oracle (Incubating), Db2 (Incubating), and Cassandra (Incubating). To make sure everything actually works, check if BINLOG is active in your database because sometimes it’s disabled by default. You will have to also create a user with access to the log.
Another cool thing about Debezium is the fact it can be used with an existing database, which pretty much means taking its snapshot and generating events based on the current contents.
How to connect all of the above with Kafka Connect?
Wait, Kafka Connect? Nobody said anything about Kafka Connect! What is it anyway?
If Apache Kafka was a house, Kafka Connect would be an additional floor built to house frequent guests. It enables you to save and read data between Kafka and external sources. With Connect, you can both import and export data using suitable source and sink connectors.
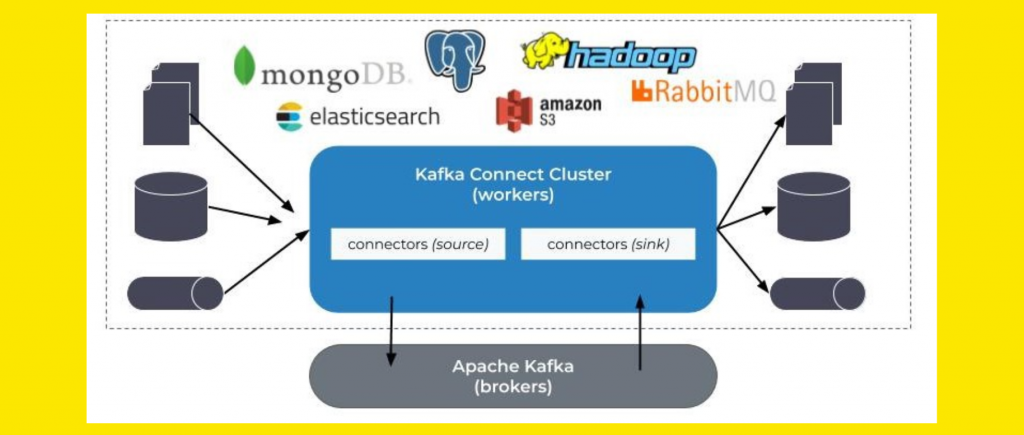
There’s a variety of connectors to choose from, which means there are many ways to use the platform without having to worry about such things as the positioning of data. It’s also possible to make some basic data transformation: filtering, flattening, or extraction. You can even use your custom data converters, so there’s a lot of wiggle space to enjoy.
We’re almost there!
We’re almost ready to bite into the data, and it’s made easier by the fact that Debezium provides its own connector. You don’t have to use any adapters or write your own solutions. And, by the way, there’s also the Debezium Engine if you’d like to use it in your own app.
Let’s also make use of a free S3 connector. It will gather the data from a specific topic, group it, export to .json, then send it to our own bucket in the S3 repository. All you need to do to make it possible is configuring the connectors.
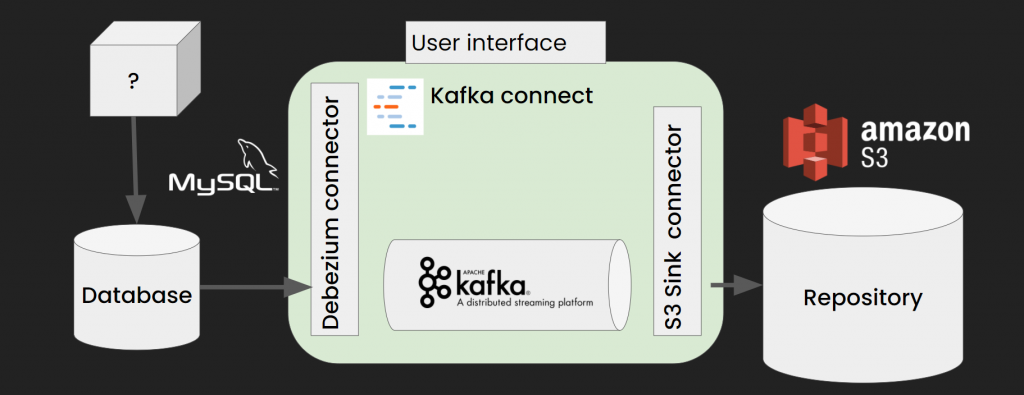
When we’re ready, we run our solution in a docker and use Lenses.io – a tool with a complete Kafka Connect platform with different connectors. It’s free only for clusters with up to 3 nodes, it’s not mandatory for production but it’s excellent for local environment setup as it speeds up the setup process. The docker image will provide the entire Kafka environment, proxy, API, and user interfaces.
It’s alive! IT’S ALIVE!
We run the Kafka Connect platform and the database with an AWS S3 mock. Now we can test our applications locally, with API and end client support. We configure the source connector so it reads the data from the database and sends the information about this data to Kafka. Then we configure the sink connector so it transfers the topic data from Kafka to the S3 repository.
This results in the current data from our selected table, and any changes of this data, being sent to the S3 repository by Kafka!
Check out the end-to-end demo of the project:
github.com/amalioadam/kafka-connect-mysql-s3
- We will use the “docker-compose up” command to launch the environment. This setup is based on the docker-compose.yaml file. Check here: kafka-connect-mysql-s3/blob/master/docker-compose.yaml
It will create 3 services, the first of which will be a Kafka cluster. We can choose predefined Debezium connectors, and then we will prepare a database and an AWS S3 Mock.
- Notice how the database setup uses the docker definition. Now let’s configure a database: kafka-connect-mysql-s3/blob/master/src_mysql/Dockerfile
- We need to create a user with all the permissions and some content for the database: kafka-connect-mysql-s3/blob/master/src_mysql/inventory.sql
- It’s important to configure it correctly. In the config file, there is a BIN log activation, which pertains to our transaction log. This log is crucial if we are to get any data (lines from 37-44):
kafka-connect-mysql-s3/blob/master/src_mysql/mysql.cnf
A single configuration can envelop the entire database. If it contains five tables, all five will be included, each with its own topic and value.
- Now it’s time to define the sink connector. For this, we have to create a data bucket in S3 first: kafka-connect-mysql-s3/blob/master/register-sink-s3-connector.json
When we have both connectors ready, we can send the data to the repository. That’s very cool, but do you know what would be even cooler? Having this data in real-time! And we should have it already, but let’s make sure – just in case. Let’s update the files and see if S3 shows the changes. If it works – ta-daa, we used two connectors to create a platform that transfers data from our legacy service to an S3 repository!
If you’re looking for more details, check out our video with all the steps:
It worked for us, it can work for you!
It really does, and you’ll get all the metrics you need to have a full and clear picture of everything that’s going on in your database. Moreover, you can even configure and use such a platform without the Schema Registry! Just mind some quirks of the software.
In Debezium, the backlog can suddenly disappear after you restart the database, but Heartbeat can help you avoid that. You may also experience table blocking during your initial scan, and here the remedy is Netflix’s tool DB LOG – it’s alternative to the Debezium CDC.
These minor hindrances shouldn’t discourage you. The benefits are much bigger. After all, you can stream data using free tools, without having to code or implement anything yourself.


