
What are your associations when someone talks about a catastrophe?
Hurricane, flood, etc. However, we are aware that our data may also be exposed to various threats. In this article, I will explain what types of threats our data is exposed to, what DR plans are, and how to protect your data from disasters.
Quite recently, there was a fire at the OVH data center. The entire server room was actually gone, unavailable. The fire has affected many companies around the world.
A tweet from the head of OVH appeared informing about the fire, recommending that DR Plans should be turned on:

We don’t know if everyone using OVH’s servers had plans of this type. It’s known, that several companies had quite big problems, e.g. Santander Bank Polska, ING Bank, Wykop, and apparently, BaseLinker which is connected to Allegro. As far as we know, the fire was caused by a malfunctioning UPS. Unfortunately, it is not known what the matter of the fire protection system looked like, usually such container server rooms should have smoke and flood detectors.
Typically, such server rooms were protected by a fire-fighting installation, mainly with halon gas, which simply cuts off the access of oxygen to the endangered place. However, the European Union is trying to prohibit the use of this type of security, because it is a great threat to people. This whole catastrophe was an event worth preparing for when creating a Disaster Recovery Plan.
Types of disasters
The Disaster Recovery Plan must describe responses to different types of problems. We can divide such disasters in terms of their location:
- local – type: building or street where the server room is located
- regional – the entire city, which also affects DR
- global – at the state or continent level
also, such disasters can be divided into:
- natural – fires, hurricanes, building collapse, etc.
- technological – hacker break-ins, application bugs that will make us lose all data, etc.
- human – sabotage, hardware theft, chemical contamination, war, pandemic, etc.
Disaster Recovery and Business Continuity
It’s a set of procedures related to crisis management that a given company must prepare. It’s a business continuity plan, it should contain all information related to unexpected events. Business continuity planning is said to deal with the point at which business continuity has been interrupted. In contrast, the DR plan, which is a subset of Business Continuity, deals with how to restore this continuity, if, in actuality, the disaster has already occurred. BC describes what to do in the event of a disaster, while DR tells how to restore business after a disaster. In our case, it is usually just a plan to get the site working again. Such procedures apply to small companies and large corporations, only the scale of the plan differs. BC may also include all countermeasures that can prevent a given catastrophe, i.e. not only how to deal with the consequences of a given catastrophe, but also how to counteract such a catastrophe – an incident.
What is Data Recovery Plan?
Data Recovery Plan is a document which, depending on the company and the size of it, may contain from one to even 400 pages. Different templates can be found on the internet, ISO certifications for Data Recovery Plan. The freedom of what is in the document depends only on the company that creates the document.
What could be included in such a document?
First of all, such a document must contain procedures that must be followed if a given incident occurs. Most often, these are procedures describing how to restore the operation of our website, service, and our business. Documents like this may describe the people responsible for implementing the DR plan, and there may also be some kind of contact with them. It’s good to provide a list of DR tests that have been performed. There may be changelogs, there may be forms describing when we ran a given test. In such a document, it is worth writing information about where our second server room is, where we can start our service, how to get to this location – address, access codes, keys, who is responsible for the second server room. There should also be a diagram of our infrastructure that we use so that, if necessary, we can create a second site that will be relatively similar. There should be server diagrams, network diagrams, what network devices are in the infrastructure, are there any load balancers, routers. All this to create a so-called hot site. Such a document may also contain more organizational information, such as what kind of insurance we have, what is insured against a given disaster, information on how to communicate with the media in the event of interrupting business continuity, everything that will help us at risk management.
This document should also include RTO (Recovery Time Objective) and RPO (Recovery Point Objective) for the whole site or for every service we have.
What is the difference between RTO and RPO?
During a service outage, the RPO specifies the amount of data that can be lost before significant harm to the business occurs. RTO stands for the amount of „actual time” that can pass before a disturbance severely and unacceptably disrupts regular business operations.
How RPO is calculated?
Recovery Point Objective, i.e. the point from which we can restore data, is most often related to the time interval, between backups, if we back up every 4 hours, we have a 4-hour RPO. Recovery Time Objective, in turn, is the time it takes to restore this data and this time is influenced by many factors such as the size of the backup – the more data, the longer it will take to restore. If we transport data to our off-site using a physical medium – tapes or disk – then the time of data import to the off-site also affects (…) we have replication, at this point, the RPO is e.g. 0. This time can also be affected by the method of data backup. F.e. if we use full/incremental backup, it is known that the restoration of such data is correspondingly longer, because we have to restore the whole thing, and then all the increments that we have done one by one, which makes RTO longer.
How to prepare a DR plan and what to pay attention to?
The planning cycle usually includes 5 steps of creating such a plan:
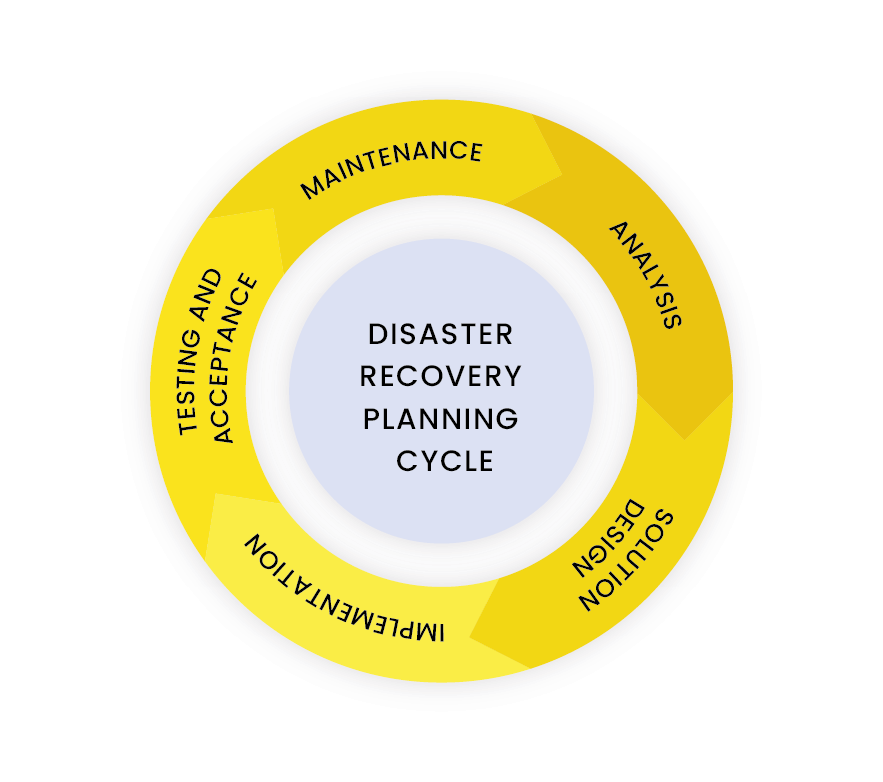
Analysis
It’s worth meeting the entire team, drawing infrastructure and networks. It is worth considering which components of our infrastructure pose the greatest danger and which affect our business the most. For example, if we use one database, it is known that this database may be the so-called SPOF (single point of failure). At this meeting, it’s worth discussing RTO and RPO, and which times we can give to the RPO and RTO, we can also consider what these times should be. It’s worth breaking down the entire infrastructure into the components we have. If we have components that are not critical, e.g. a live chat on a website that is operated by a separate service, then consider whether it’s important or not. Maybe here the times of RPO and RTO are not quite crucial, but it’s worth having it all written down in this document.
Preparation of the solution
Based on this analysis, it is necessary to consider how we want to make a DR plan, how to best perform backups, it is worth considering three-stage backups, there is a fairly popular saying that it is worth having your data in three places:
- live – that is, in production
- on-site – on the server where the production is
- off-site – that is, outside production
This is a way that minimizes the loss of our data.
In preparing the solution, we must consider the procedures and all steps, how we can restore data, how we can restore our business.
Implementation
Then there is the implementation, which is writing this document. It’s worth printing it, laminating it, it’s good that the document is available in the company, and the new employee who comes to work can understand everything about the DR plan.
Acceptance tests
The next step is acceptance testing, which is the most important part of the overall DR plan. If the plan is not tested, at the same time it might not exist. If we don’t test it, we don’t know if it works. That’s why it’s worth having a form and a test schedule in the document. Such tests can be performed every two weeks, every month, or as planned.
Maintenance
In the end, we have maintenance, which is also very important. Our system is changing, new functionalities are added, RTO and RPO times change. It’s good to repeat the whole process if there are any changes or try to meet as a team from time to time and consider whether something has changed or whether it would be worth updating our plan. Such a document must be approved by the team responsible for the DR plan, by the team responsible for our business, by the management board. Ideally, everyone should be aware that such a thing exists.
You might also be interested in the article:
Hosting Without a Server? Meet Serverless, and See How You Can Take Advantage of It
Disaster Recovery Service Levels
This is something that the Share group created, mainly responsible for IP mainframes. In 1992, there were 7 tiers, in 2012 the list was increased by 1 more tier. It’s about the so-called cold site and hot site. A cold site is a server room that is prepared to receive our infrastructure and our business. It is a building with a fire protection system, raised floor, and internet connection. In turn, the hot site is the second server room that is ready to take over the internet traffic from us, practically immediately. It can also be a server room connected to offices, somewhere where the entire company and employees can move. It is not only a technological infrastructure, there may also be rooms for employees so that you can work there if necessary.
- Tier 0 – No off-site data. Recovery is only possible using on-site systems.
- Tier 1 – Physical backup with a cold site. Data, likely on tape, is transported to an off-site facility that does not have the necessary hardware installed.
- Tier 2 – Physical backup with a hot site. Data, likely on tape, is transported to an off-site facility that has the necessary hardware installed to support key systems of the primary site.
- Tier 3 – Electronic vaulting. Data is electronically transmitted to a hot site.
- Tier 4 – Point-in-time copies/active secondary site. Vital data is copied across the primary and secondary sites, each site backing up the other. Disk is often used in this tier.
- Tier 5 – Two-site commit/transaction integrity. Data is continuously transmitted across sites.
- Tier 6 – Minimal to zero data loss. Recovery is instantaneous, often involving disk mirroring or replication.
- Tier 7 – Later added to include automation, and it represents the highest level of availability in disaster recovery scenarios. In general, while the ability to recover improves with the next highest tier, costs also increase.
The Importance of Disaster Recovery
When faced with an unexpected catastrophe, creating an appropriate and smart Disaster Recovery plan helps companies minimize the very real threat of economic damage, operational disruption, and brand reputation. It enables a well-organized and managed recovery, ensuring protection and a smooth return to operation. A Disaster Recovery plan is the true measure of a business’s prosperity when confronted with unexpected results, since it has become a required feature of all enterprises.
At fireup.pro we work with you to recognize, understand, and help you achieve your objectives. We create a feedback loop that enables us to improve quickly and effectively. We’re concerned about both the customer and employee sides of the applications you implement. For us, it’s the only way anyone can be successful in business.


