
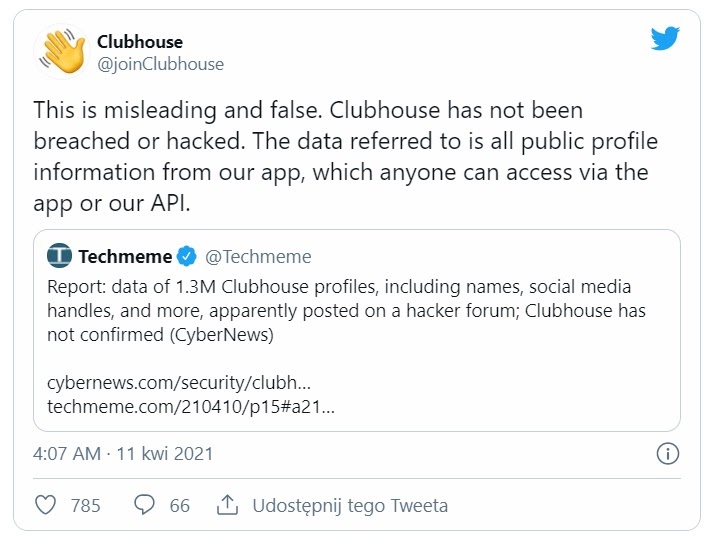
In recent days, news of another „data leak” has spread worldwide. The Cyber News portal reports that a database containing over 1.3 million records from the Clubhouse app has been published by hackers. Is so-called data scraping a new trend among cybercriminals looking to profit from selling data?
Data scraping, which involves automatically collecting data from publicly available sources, is becoming increasingly popular. Unlike traditional data breaches, where hackers gain access to private information by breaking security measures, data scraping involves gathering data that is already publicly accessible but in an organized and large-scale manner. In the case of Clubhouse, data such as account names, user IDs, profile pictures, and connections to other social media platforms were collected and shared as a database.
Table of Contents
What is Clubhouse
It’s one of the fastest-growing social media channels. Clubhouse is a modern social media application based on audio chats. Users can listen in on conversations, interviews, and discussions between interesting people on a variety of topics – similar to a podcast, but live. Clubhouse is invite-only. You can’t simply download it from the app store and create an account; you need to be invited by an existing member. Real-world elitism, but online. The app is currently available only on iOS.
However, more and more often, instead of focusing on the app’s innovation or its growing user base, concerns are being raised about security issues, particularly regarding the synchronization of contacts through the app.
Database with Clubhouse users, for free
Hacker forums are a goldmine of interesting content. On one of them, a fresh user uploaded a link to a SQL database containing 1.3 million records, and it was spotted quite quickly.

The data that was shared primarily includes Account Names, User IDs, Photo URLs, Twitter nicknames, Instagram nicknames, Number of Followers, Number of Following, Account Creation Time, and the „Invited by” user profile. Notably, among the stolen data are not only user numbers but also contacts saved on their phones, suggesting that the app synchronizes user data to simplify communication.
It’s important to note that this is not a leak of sensitive data. All of this information is publicly available and, similar to LinkedIn, has been pulled directly from the API and aggregated. However, it is still very intriguing data that can be exploited by various parties.
With the number of active accounts in the app now estimated at approximately 10 million, this situation is quite serious. The data may also include more sensitive information. CyberNews, which published the reports, highlighted that this information could be used for phishing attacks and identity theft.
Clubhouse: This is not a leak
Clubhouse CEO Paul Davison said that the report prepared by Cyber News was false, describing it as a „clickbait”. He also claims that the platform has not registered any data breach, and all information collected in the SQL database is available to everyone using the Clubhouse API.
API has its own rules, as has recently emerged from the Supreme Court judgment in the case of Google and Oracle. However, the possibility of any user scraping and aggregating such enormous amounts of data may raise some concerns. Usually, API is either publicly open or guarded by some kind of key authorization, f.e. OAuth. Maybe this particular API wasn’t also defended by rate-limiting which is a normal security pattern. APIs are also usually protected by some kind of EULA, which can forbid scraping.
What is Web scraping and how it works?
Web scraping refers to the automated collection of organized web data. Web data extraction is another term for it. Price tracking, news monitoring, lead generation, and market research are only a few examples. People and companies who want to take advantage of the huge amount of publicly available data use web data extraction.
Web scraping uses intelligent automation to retrieve hundreds, millions, or even billions of data points from the internet’s almost limitless expanse using intelligent automation.
What are the recent trends in web scraping?
- Web scraping is becoming increasingly advanced thanks to new technologies and tools. Here are some of the latest trends in this field:
- Cloud-Based Scraping Platforms: More companies are leveraging cloud solutions for data collection. This allows them to scale their operations and gather data on a massive scale without the need to invest in infrastructure.
- Application of Machine Learning: Machine learning is being used more frequently for automated parsing and data extraction from websites. This makes the process more efficient and less reliant on user intervention.
These trends demonstrate that web scraping is becoming more sophisticated and accessible to a wider audience, which could lead to an increase in large-scale data collection activities.
So, is data scraping legal?
Web scraping itself is not illegal. But there are some other restrictions, that hold businesses back from using web data scrapers. Let’s see them:
1. Websites expressively forbid web scraping within their website terms and conditions.
2. Copyright – it may lead to a claim for copyright infringement.
3. Database rights – These rights are infringed when as a whole, or a part of a database is extracted without the owner’s consent.
4. Trademarks Reproducing a website owner’s trademarks without their consent, could lead to a claim for trademark infringement or passing off.
5. Data protection – Scraping for information on individuals (in some cases considered as “personal data”), without their knowledge, could infringe data protection laws.
6. Criminal Damage – It’s an offense to cause criminal damage to a computer (including damage to data) or to use a computer to gain to access data without proper authorization.
Laws are country and locality specific, but legality is entirely dependent on the legal jurisdiction. Scraping or collecting publicly accessible information is not illegal; if it were, Google would not operate as a corporation because they scrape data from any website in the world.
How do you protect against web scraping?
Basically, hindering scraping means making it difficult for scripts and machines to extract data from your website while ensuring that it remains accessible to real users and search engines. Unfortunately, this is challenging, and compromises must often be made between preventing scraping and maintaining accessibility for genuine users and search engines. Users may face various risks, including data breaches, which could affect not only their own information but also the contacts stored on their phones.
How to prevent scraping
You can use some general methods to detect and deter scrapers.
Monitor your logs and traffic patterns; limit access if you notice unusual activity:
Check your logs regularly, and in case of many similar actions from the same IP address, block or limit access.
Here are a few suggestions:
- Detect unusual activity:
If you see unusual activity, such as many similar requests from a specific IP address, someone looking at an excessive number of pages, or performing an unusual number of searches, you can prevent access, or show a captcha for subsequent requests.
- Rate limiting:
Only allow users (and scrapers) to perform a limited number of actions in a certain time – for example, only allow a few searches per second from any specific IP address or user. This will slow down scrapers, and make them ineffective. You could also show a captcha if actions are completed too fast or faster than a real user would.
- Don’t just monitor or rate limit by IP address – use other indicators too:
If you block or rate limit, don’t just do it on a per-IP address basis; you can use other indicators and methods to identify specific users or scrapers. Some indicators which can help you identify specific users/scrapers contain:
- How fast users fill out forms, and where on a button they click;
You can gather a lot of information with JavaScript, such as screen size/resolution, timezone, etc; you can use this to identify users.
- HTTP headers and their order, especially User-Agent.
As an example, if you get many requests from a single IP address, all using the same User-agent, the screen size (determined with JavaScript), and the user always clicks on the button in the same manner and at regular intervals, it’s probably a screen scraper, and you should temporarily block similar requests. This way you won’t discomfort real users on that IP address, eg. in case of a shared internet connection.
You can also look at the ‘Referer’ header. Usually, web scrapers don’t follow the normal flow of web navigation. Sometimes the author of the web scraper doesn’t create this header and you can detect it on server logs.
As you can identify similar requests, even if they come from different IP addresses, indicative of distributed scraping (a scraper using a botnet or a network of proxies). If you get a lot of otherwise identical requests, but they come from different IP addresses, you can block them. Again, be aware of not unintentionally blocking real users.
This can be effective against screenscrapers which run JavaScript, as you can get a lot of information from them.
Like it or not – Scraping is practically legal
There is a thin line between the legal and illegal aspects of web scraping. Publicly available APIs are particularly tempting targets. Clubhouse is another organization that has fallen victim to large-scale data scraping, though this is far from being considered a “leak.”
In contrast to Clubhouse, Twitter’s Spaces feature allows for more dynamic live discussions, attracting experts and active users from various fields. However, the topic remains highly debatable.
If you need more information about data security, feel free to contact us or check fireup.pro blog.


