
Systemy przetwarzania danych są dziś fundamentem nowoczesnych platform cyfrowych. Łączą dane z wielu źródeł, przetwarzają je w sposób ciągły i dostarczają wiarygodne wyniki, które napędzają decyzje biznesowe, algorytmy rankingowe czy modele analityczne.
Aby taki system był skalowalny, wydajny i odporny na błędy, musi być odpowiednio przetestowany – nie tylko na poziomie backendu, ale całego procesu przetwarzania danych end-to-end.
W tym artykule pokazujemy, jak w praktyce wygląda testowanie systemów przetwarzania danych, na bazie doświadczeń z projektu realizowanego w środowisku opartym o eventy, message brokery i agregacje dzienne.
Table of Contents
Czym jest system przetwarzania danych?
System przetwarzania danych to rozwiązanie, które:
- zbiera dane z jednego lub wielu źródeł,
- oczyszcza i normalizuje dane,
- przetwarza je zgodnie z określonymi algorytmami,
- agreguje wyniki,
- zapisuje rezultaty i udostępnia je innym systemom.
Kluczowe jest to, że ten proces jest cykliczny i ciągły. Dane nie są dostarczane jednorazowo – system stale odbiera nowe zdarzenia, przelicza je i aktualizuje wyniki.
Dlaczego testowanie przetwarzania danych jest tak ważne?
Na początku łatwo pomylić testy przetwarzania danych ze „zwykłymi testami backendu”. Dopiero praktyka pokazuje, że:
➡️ testujemy nie tylko API czy logikę biznesową,
➡️ ale również przepływ danych, ich transformację, agregację i spójność w czasie.
W projektach opartych o duże wolumeny danych i asynchroniczne przetwarzanie, brak odpowiednich testów prowadzi do:
- błędnych wyników,
- duplikatów,
- niespójnych agregatów,
- problemów wydajnościowych.
Cele testów systemów przetwarzania danych
Testy przetwarzania danych mogą realizować kilka kluczowych celów:
- Poprawność algorytmów
Sprawdzenie, czy dane po przetworzeniu są zgodne z oczekiwaniami biznesowymi. - Wydajność i czas odpowiedzi
Jak system zachowuje się przy dużej liczbie zdarzeń? Jak szybko generuje wyniki? - Skalowalność
Czy system radzi sobie ze wzrostem wolumenu danych i liczby źródeł? - Spójność danych
Czy dane z różnych źródeł są prawidłowo scalane i agregowane? - Odporność na błędy
Czy błędne dane wejściowe nie zatrzymują całego procesu przetwarzania?
Co może być przedmiotem testów?
W testach przetwarzania danych nie ograniczamy się do jednego elementu. Testowanym obiektem może być:
- pojedyncza funkcja przetwarzająca dane,
- cały mikroserwis,
- procedura agregująca dane,
- integracja pomiędzy systemami,
- pełny pipeline danych end-to-end.
Jak testować systemy przetwarzania danych?
Testy jednostkowe, integracyjne i systemowe
Skuteczne testowanie wymaga połączenia różnych poziomów testów:
- testy jednostkowe – sprawdzające pojedyncze transformacje danych,
- testy integracyjne – weryfikujące komunikację pomiędzy komponentami,
- testy systemowe – obejmujące cały proces przetwarzania danych,
- testy end-to-end – potwierdzające, że dane od źródła trafiają do systemu docelowego w poprawnej postaci.
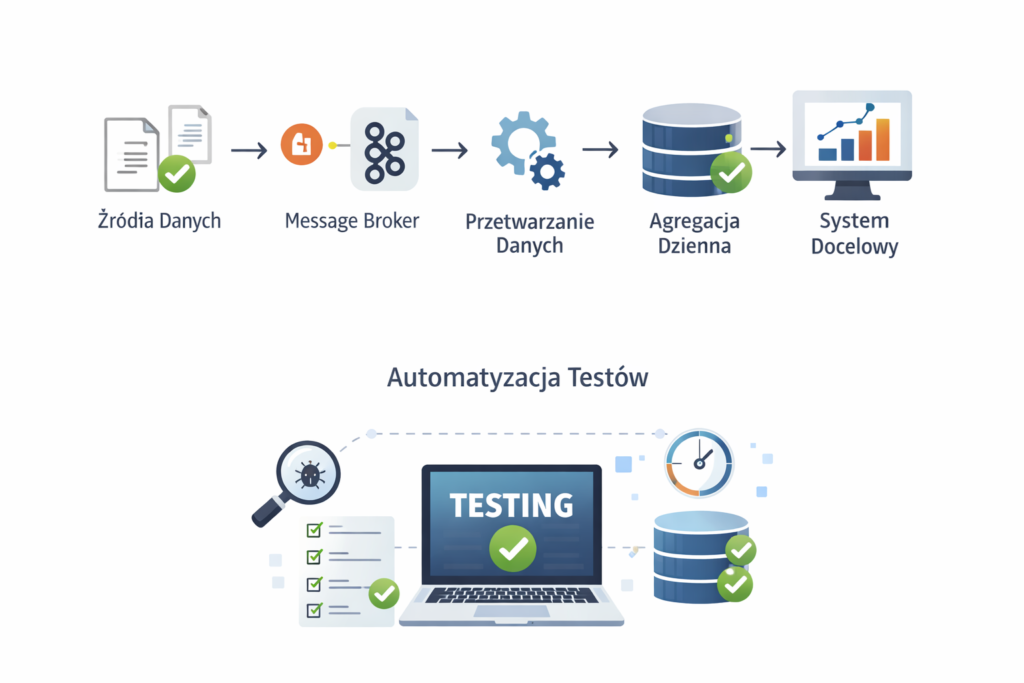
Automatyzacja testów
Automatyzacja pozwala:
- testować duże wolumeny danych,
- powtarzać scenariusze w sposób deterministyczny,
- szybciej wykrywać regresje.
W praktyce jest to niezbędne przy systemach opartych o eventy i message brokery.
Przykładowa architektura przetwarzania danych
W opisywanym projekcie dane:
- trafiały w postaci zdarzeń do message brokera (Kafka, RabbitMQ),
- były konwertowane z JSON do formatu Avro,
- przechodziły przez warstwę agregacji,
- były zapisywane jako dzienne agregaty danych,
- zasilały kolejne systemy analityczne i rankingowe.
Taki układ pozwalał na:
- elastyczne przetwarzanie danych,
- obsługę wielu konsumentów,
- separację odpowiedzialności pomiędzy serwisami.
Przygotowanie danych testowych
Pierwszym krokiem było zdefiniowanie danych wejściowych:
- z jednego lub wielu źródeł,
- w postaci JSON-ów lub prostych struktur tekstowych,
- przygotowanych jako szablony z dynamicznymi polami.
Dzięki temu możliwe było szybkie generowanie różnych scenariuszy testowych bez budowania złożonych obiektów w kodzie.
Wysyłanie i odczyt danych w testach
W testach wykorzystywano głównie:
- Kafka i RabbitMQ do wysyłania zdarzeń,
- Kafka oraz REST API do odczytu danych po przetworzeniu.
Kluczowe było sprawdzanie:
- czy dane w ogóle się pojawiły,
- czy zostały poprawnie przekształcone,
- czy są zgodne ze schemą (np. Avro),
- czy nie generują duplikatów.
Weryfikacja przetworzonych danych
Każdy etap przetwarzania był weryfikowany osobno:
- poprawność pojedynczych rekordów,
- agregacja danych per źródło,
- agregacja per podmiot (np. shipper),
- agregacja per dzień,
- łączenie danych z różnych źródeł.
Szczególną uwagę zwracano na eliminację duplikatów, które są jednym z najczęstszych problemów w systemach event-driven.
Odporność systemu na błędne dane
Jednym z kluczowych wniosków było to, że:
źle spreparowane dane testowe nie mogą zatrzymywać całego procesu przetwarzania.
System musi być odporny na:
- niezgodność danych ze schemą,
- częściowo błędne eventy,
- nieoczekiwane wartości.
To wymaga zarówno odpowiednich zabezpieczeń po stronie systemu, jak i świadomego podejścia do testów.
Testy agregacji dziennych i danych historycznych
Agregaty dzienne były kluczowe dla dalszych obliczeń:
- dane z jednego dnia były sumowane,
- dane z różnych źródeł łączone w jeden wynik,
- dane historyczne (np. z 30, 60 czy 365 dni) wykorzystywane w algorytmach rankingowych.
Testy sprawdzały, czy:
- agregaty są poprawnie liczone,
- daty są prawidłowo przypisywane,
- dane z dzisiejszego dnia i dni poprzednich są właściwie rozróżniane.
Testowanie algorytmów opartych o przetworzone dane
Na końcu pipeline’u dane zasilały algorytmy rankingowe, w których:
- liczone były wskaźniki złożone z wielu składowych,
- wykorzystywano dane historyczne,
- pojedyncze zdarzenia mogły mieć istotny wpływ na końcowy wynik.
Testy wymagały precyzyjnego przygotowania danych, tak aby możliwe było przewidzenie i asercja konkretnych wartości.
Testy end-to-end – ostatni krok
Na końcu wykonywane były testy end-to-end, które:
- sprawdzały pełną ścieżkę danych,
- potwierdzały, że zdarzenie wysłane na message broker dociera do systemu docelowego,
- obejmowały wyłącznie podstawowe scenariusze typu happy path.
Ich celem nie była pełna walidacja logiki, ale upewnienie się, że cały ekosystem działa spójnie.
Wnioski: testy przetwarzania danych to coś więcej niż backend
Najważniejszy wniosek z projektu jest prosty: testy przetwarzania danych to osobna kategoria testów, która wymaga:
- zrozumienia całego przepływu danych,
- świadomości wpływu pojedynczych zdarzeń na agregaty,
- odpowiedniej strategii testowej,
- automatyzacji i izolowania poszczególnych etapów.
To podejście pozwala budować systemy odporne, skalowalne i gotowe na realne obciążenia produkcyjne.
Jak testować systemy przetwarzania danych?
Testy jednostkowe, integracyjne i systemowe
Skuteczne testowanie wymaga połączenia różnych poziomów testów:
- testy jednostkowe – sprawdzające pojedyncze transformacje danych,
- testy integracyjne – weryfikujące komunikację pomiędzy komponentami,
- testy systemowe – obejmujące cały proces przetwarzania danych,
- testy end-to-end – potwierdzające, że dane od źródła trafiają do systemu docelowego w poprawnej postaci.
Automatyzacja testów
Automatyzacja pozwala:
- testować duże wolumeny danych,
- powtarzać scenariusze w sposób deterministyczny,
- szybciej wykrywać regresje.
W praktyce jest to niezbędne przy systemach opartych o eventy i message brokery.
Przykładowa architektura przetwarzania danych
W opisywanym projekcie dane:
- trafiały w postaci zdarzeń do message brokera (Kafka, RabbitMQ),
- były konwertowane z JSON do formatu Avro,
- przechodziły przez warstwę agregacji,
- były zapisywane jako dzienne agregaty danych,
- zasilały kolejne systemy analityczne i rankingowe.
Taki układ pozwalał na:
- elastyczne przetwarzanie danych,
- obsługę wielu konsumentów,
- separację odpowiedzialności pomiędzy serwisami.
Przygotowanie danych testowych
Pierwszym krokiem było zdefiniowanie danych wejściowych:
- z jednego lub wielu źródeł,
- w postaci JSON-ów lub prostych struktur tekstowych,
- przygotowanych jako szablony z dynamicznymi polami.
Dzięki temu możliwe było szybkie generowanie różnych scenariuszy testowych bez budowania złożonych obiektów w kodzie.
Wysyłanie i odczyt danych w testach
W testach wykorzystywano głównie:
- Kafka i RabbitMQ do wysyłania zdarzeń,
- Kafka oraz REST API do odczytu danych po przetworzeniu.
Kluczowe było sprawdzanie:
- czy dane w ogóle się pojawiły,
- czy zostały poprawnie przekształcone,
- czy są zgodne ze schemą (np. Avro),
- czy nie generują duplikatów.
Weryfikacja przetworzonych danych
Każdy etap przetwarzania był weryfikowany osobno:
- poprawność pojedynczych rekordów,
- agregacja danych per źródło,
- agregacja per podmiot (np. shipper),
- agregacja per dzień,
- łączenie danych z różnych źródeł.
Szczególną uwagę zwracano na eliminację duplikatów, które są jednym z najczęstszych problemów w systemach event-driven.
Odporność systemu na błędne dane
Jednym z kluczowych wniosków było to, że: źle spreparowane dane testowe nie mogą zatrzymywać całego procesu przetwarzania.
System musi być odporny na:
- niezgodność danych ze schemą,
- częściowo błędne eventy,
- nieoczekiwane wartości.
To wymaga zarówno odpowiednich zabezpieczeń po stronie systemu, jak i świadomego podejścia do testów.
Testy agregacji dziennych i danych historycznych
Agregaty dzienne były kluczowe dla dalszych obliczeń:
- dane z jednego dnia były sumowane,
- dane z różnych źródeł łączone w jeden wynik,
- dane historyczne (np. z 30, 60 czy 365 dni) wykorzystywane w algorytmach rankingowych.
Testy sprawdzały, czy:
- agregaty są poprawnie liczone,
- daty są prawidłowo przypisywane,
- dane z dzisiejszego dnia i dni poprzednich są właściwie rozróżniane.
Testowanie algorytmów opartych o przetworzone dane
Na końcu pipeline’u dane zasilały algorytmy rankingowe, w których:
- liczone były wskaźniki złożone z wielu składowych,
- wykorzystywano dane historyczne,
- pojedyncze zdarzenia mogły mieć istotny wpływ na końcowy wynik.
Testy wymagały precyzyjnego przygotowania danych, tak aby możliwe było przewidzenie i asercja konkretnych wartości.
Testy end-to-end – ostatni krok
Na końcu wykonywane były testy end-to-end, które:
- sprawdzały pełną ścieżkę danych,
- potwierdzały, że zdarzenie wysłane na message broker dociera do systemu docelowego,
- obejmowały wyłącznie podstawowe scenariusze typu happy path.
Ich celem nie była pełna walidacja logiki, ale upewnienie się, że cały ekosystem działa spójnie.
Wnioski: testy przetwarzania danych to coś więcej niż backend
Najważniejszy wniosek z projektu jest prosty: testy przetwarzania danych to osobna kategoria testów, która wymaga:
- zrozumienia całego przepływu danych,
- świadomości wpływu pojedynczych zdarzeń na agregaty,
- odpowiedniej strategii testowej,
- automatyzacji i izolowania poszczególnych etapów.
To podejście pozwala budować systemy odporne, skalowalne i gotowe na realne obciążenia produkcyjne.


