
Cześć,
Chciałabym opowiedzieć o tym, jak wygląda architektura LLM w praktyce. Co faktycznie dzieje się pod spodem?
Większość z nas korzysta dziś z AI. Zadajemy pytania, generujemy kod, analizujemy dane. Rzadko jednak zastanawiamy się, co znajduje się pod spodem.
A pod spodem nie ma żadnej samoświadomości. Jest statystyka. Jest zbiór elementów, które współpracują ze sobą i tworzą iluzję inteligencji. I właśnie o tym jest architektura systemów agentowych.
Dlatego, żeby zrozumieć, dlaczego coś działa (albo nie działa) trzeba spojrzeć szerzej. Nie tylko na model, ale na cały system. Bo to zawsze jest system, nie tylko model. Architektura LLM w praktyce to projektowanie całego układu: od agenta, przez pamięć i narzędzia, po zarządzanie kontekstem, kosztami i bezpieczeństwem.
Jeśli tego nie zrozumiemy, trudno będzie zrozumieć, dlaczego coś działa świetnie… a coś innego kończy się kompletną bzdurą, która brzmi bardzo przekonująco.
Użytkownik, agent i LLM – kto tu właściwie robi robotę?
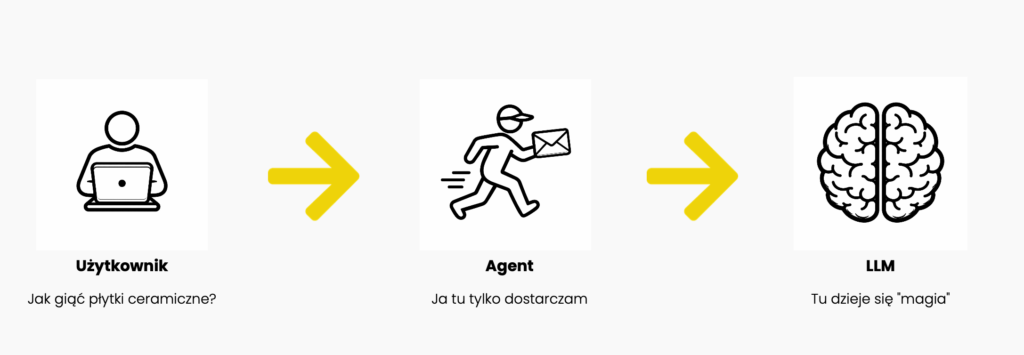
Zacznijmy od podstawowego przepływu.
Agent brzmi futurystycznie, ale w praktyce to po prostu konwencjonalny kod. Skrypt. Nie ma żadnej superinteligencji. Nie analizuje pytania, nie rozważa jego sensu. On tu tylko dostarcza.
LLM generuje odpowiedź. Zwykle uprzejmą, często długą. Zdarza się, że zaczyna od „Świetne pytanie!”, nawet jeśli pytanie było zupełnie nietrafione.
Ma jednak jedną zasadniczą wadę: bardzo krótką pamięć.
Model operuje wyłącznie na tym, co dostanie w danym momencie jako input. Każde zapytanie to dla niego nowy start. Jeśli wydaje nam się, że pamięta poprzednią rozmowę, to dlatego, że agent zapisuje historię i dołącza ją do kolejnych zapytań.
Tak powstaje kontekst.
Long-term memory – czyli dlaczego czat „pamięta”
Skoro model nic nie pamięta, to dlaczego możemy prowadzić rozmowę?
Bo pamięta agent.
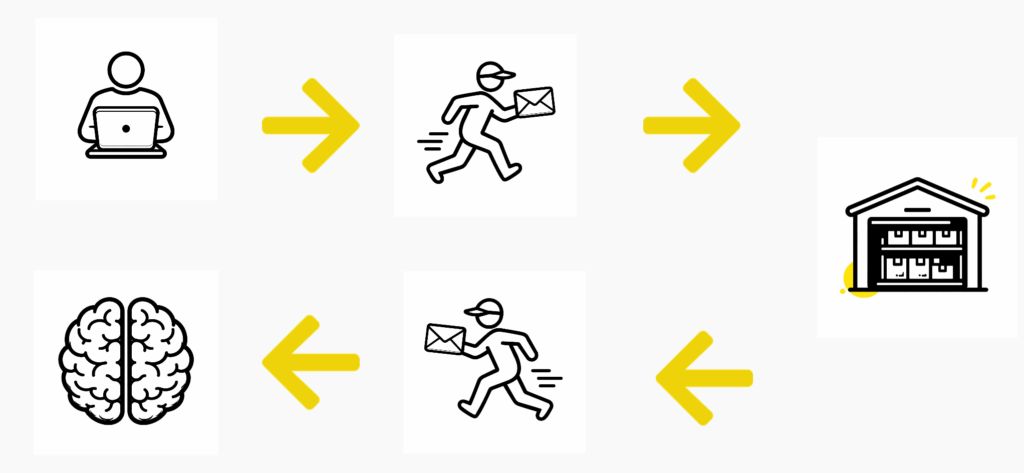
Po każdej odpowiedzi agent zapisuje konwersację w tzw. long-term memory. To może być coś prostego jak plik JSON, może być baza wektorowa w bardziej złożonym systemie. Przy kolejnym pytaniu agent:
- Idzie do magazynu.
- Zbiera historię rozmowy.
- Dokleja ją do nowego promptu.
- Wysyła całość do LLM.
I tak powstaje coraz większa paczka danych. Magazyn rośnie, prompt pęcznieje. Im dłuższa rozmowa, tym większy input trafia do modelu.
Narzędzia i ping-pong
Systemy agentowe to nie tylko chat.
LLM może dostać listę narzędzi. Każde narzędzie ma opis: kiedy można go użyć i jak powinno wyglądać wywołanie.
Model może zwrócić instrukcję: „wywołaj to narzędzie z takimi parametrami”. Agent wykonuje instrukcję, bierze wynik i wysyła go z powrotem do modelu.
Czasem powstaje z tego ping-pong:
model → agent → narzędzie → agent → model → …
Zdarza się, że ta pętla zaczyna kręcić się w nieskończoność i widać, że do niczego to nie prowadzi. Wtedy trzeba ją przerwać.
I tu pojawia się kolejny element architektury.
Liczniki tokenów – czyli ile to kosztuje
Płacimy za wszystko, co model musi przeczytać. Płacimy za wszystko, co wygeneruje.
Każde słowo w kontekście to tokeny. Każde narzędzie, każda poprzednia odpowiedź – to też tokeny. Dlatego kultura osobista w dobie tokenizacji to trochę luksus 🙂
To nie jest detal. To realny aspekt projektowania architektury LLM.
Jak LLM „myśli”: Od słowa do prawdopodobieństwa
LLM nie rozumie znaczeń, a jedynie statystyczne korelacje między liczbami. Proces wygląda następująco:
Tokenizacja: Tekst jest krojony na kawałki (tokeny). Model nie widzi liter, tylko numeryczne identyfikatory fragmentów słów (np. „ros” + „ół”).
Embedding: Każdy token staje się punktem w przestrzeni wielowymiarowej (wektorem). Słowa o podobnym kontekście (np. „rosół” i „zupa”) lądują blisko siebie.
Mechanizm atencji: To tu model „rozumie” kontekst. Analizuje powiązania między wszystkimi słowami w zdaniu – dzięki temu wie, że gdy gotujesz rosół, słowo „woda” dotyczy garnka, a nie czajnika.
Predykcja: Model nie „odpowiada”, on oblicza statystykę: jaki token powinien wystąpić jako następny w danym ciągu.
Detokenizacja: Wybrany numer tokena zostaje zamieniony z powrotem na czytelny tekst.
Klucz do zrozumienia: Model nie wie, czym fizycznie jest rosół. On po prostu wie, że po słowach „babcia ugotowała” w ogromnej bazie tekstów z ogromnym prawdopodobieństwem występowały współrzędne wektora „rosół”.

Ograniczone okno kontekstowe
Wszystko, co wrzucamy do modelu, musi zmieścić się w jego oknie kontekstowym. A to okno jest ograniczone i ściśle związane z modelem.
Do tego okna próbują się zmieścić:
- prompt użytkownika,
- historia konwersacji,
- lista narzędzi,
- dodatkowe ustawienia.
Przy bardzo długich rozmowach część historii po prostu przestaje być widoczna. Dodatkowo działa zjawisko Lost in the Middle. Modele lepiej pamiętają początek i koniec kontekstu. To, co było w środku, może się rozmyć. Więcej nie zawsze znaczy lepiej.
Halucynacje – naturalna konsekwencja
Halucynacje to nie usterka. To konsekwencja natury LLM. Model ma wygenerować najbardziej prawdopodobny ciąg wyrazów. Jeśli nie ma pełnych danych – i tak coś wygeneruje.
Na to wpływa:
- rozmiar modelu,
- dokładność wag,
- ilość i jakość danych treningowych,
- długość treningu,
- dostęp do zewnętrznych danych,
- jakość promptu.
Ale nawet przy najlepszych parametrach to wciąż probabilistyka.
Zatruwanie kontekstu
Jeśli w jednym wątku rozmawiam o tacosach, dipach i cheddarze, a później w tym samym wątku proszę o wygenerowanie pytań do teleturnieju, model może dalej operować w świecie tacosów.
To jest zatruwanie kontekstu. Czasem widać to od razu i jest to zabawne. W projektach technicznych bywa znacznie mniej oczywiste.
Prompt injection i jailbreak
W klasycznym IT kod (instrukcje) jest oddzielony od danych (wpisów użytkownika).
W LLM ten podział nie istnieje – model widzi wszystko jako jeden ciąg znaków o tym samym priorytecie. Nie potrafi odróżnić „rozkazu” twórcy od „oszustwa” użytkownika.
Prompt injection to przejęcie kontroli nad logiką (nadpisanie instrukcji).
Jailbreak to złamanie blokad etycznych (wymuszenie zakazanych treści).
Zabezpieczenia to tylko statystyka: możemy prosić model, by nas słuchał, ale sprytny prompt zawsze może przeważyć szalę prawdopodobieństwa na stronę napastnika.
Jak z tym pracuję w praktyce
Po pierwsze: sprawdzam.
Nie traktuję odpowiedzi modelu jako ostatecznej prawdy. Review jest kluczowy.
Po drugie: pozwalam mu uczyć się na błędach. Model może wygenerować testy, uruchomić je w pętli, poprawić swój output. Ale ja sprawdzam efekt końcowy.
Po trzecie: least privilege także dla LLM.
Nie daję mu dostępu do wszystkiego. Nawet jeśli korzysta z read-only repliki, może wygenerować output, którego nie chcemy zobaczyć w złym miejscu.
Po czwarte: nakarm go wiedzą. Jeśli pracuję z konkretną technologią, daję mu dokumentację, zasady repozytorium, kontekst projektowy. To zwiększa jakość odpowiedzi.
Po piąte: sprzątam kontekst. Otwieram nowe wątki, gdy zmieniam temat. Robię podsumowania. Nie pozwalam, żeby prompt puchł bez kontroli.
Dlaczego to działa — i dlaczego nie działa
Działa, bo LLM świetnie odwzorowuje wzorce językowe i potrafi operować na dużej ilości danych.
Nie działa, bo:
- to statystyka, nie świadomość,
- nie ma ugruntowanego rozumowania,
- okno kontekstowe jest ograniczone,
- halucynacje są naturalne,
- kontekst można zatruć,
- nie ma twardej granicy między instrukcją a inputem.
Architektura LLM w praktyce to umiejętność projektowania systemu, który bierze te ograniczenia pod uwagę.Dla mnie to po prostu narzędzie. Bardzo potężne. Bardzo użyteczne. Ale nadal narzędzie.
I tak je traktuję.


