
Most articles about reviewing AI-generated code start with a checklist. This one starts earlier with the question every checklist skips: should you even be reading this code at all?
I know what you’re thinking. But before you answer „obviously” picture a typical Tuesday on a team with high AI adoption. Cursor generates a PR. Then another. Then three more, because someone ran an agent against the backlog. By noon you have more diffs in the queue than you saw all of last week. Reviewers (the same people as a year ago, with the same number of hours) start skimming instead of reading.
The data backs this up brutally: with heavy AI usage, the number of merged PRs grows by 98%, but review time grows by 91%. Senior engineers need an average of 4.3 minutes per AI suggestion. For human-written code, that’s 1.2 minutes. And time is running out.
Table of Contents
Why the old model doesn’t fit the new shape of work
Code review in its current form only became widespread around 2012–2014. It was a response to a specific problem: people writing code needed a fresh set of eyes from someone who understood the context and could catch logical errors.
That model had one hidden assumption: code is read by someone who understands it. Line by line, with full knowledge of the system. An agent generates 500 lines in fifteen minutes. The reviewer gets a diff the size of a sprint and if they’re being honest with themselves skims, not reads.
Some teams try to solve this cleverly: they run the code through another model. Fresh eyes, just mechanical ones. The problem is that both models share the same blind spots and neither of them knows it.
What’s more, AI code generates 1.7x more issues than human-written code, and nearly half of developers say debugging AI-written code takes them more time than fixing code written by humans. Reviewer fatigue is real. The more code piles into the queue, the more things slip through the net.
Should you review AI-generated code? Yes, but not the way you think
Instead of asking „is this code written correctly?” it’s worth asking „did we define the problem this code is supposed to solve correctly?”
The human checkpoint makes sense. We’re just setting it too late. Before an agent writes its first line, someone on the team should already know: exactly what needs to be built, what the constraints are, and how we’ll know it works. Spec, acceptance criteria, domain contracts that’s human work. Code is just the downstream effect of those decisions.
We’re not reinventing the wheel. The checkpoint used to sit at the very end. Waterfall, big sign-off, then production. We moved it into the middle and called it CI. We can move it again.
Traditional review vs. spec-driven approach: what changes
| Traditional code review | Spec-driven approach | |
| Where is the human checkpoint | After writing code (diff review) | Before writing code (spec, AC) |
| What does a human approve | Implementation line by line | Intent – acceptance criteria, contracts |
| What catches bugs | Reviewer (human or AI) | Deterministic tests, linters, SAST |
| Scalability | Doesn’t scale with 10x more PRs | Scales – guardrails run automatically |
| Where does risk lie | Reviewer fatigue, missed bugs | Poorly defined spec |
| When is human review required | Always, on every PR | For critical domains: auth, payments, DB schema |
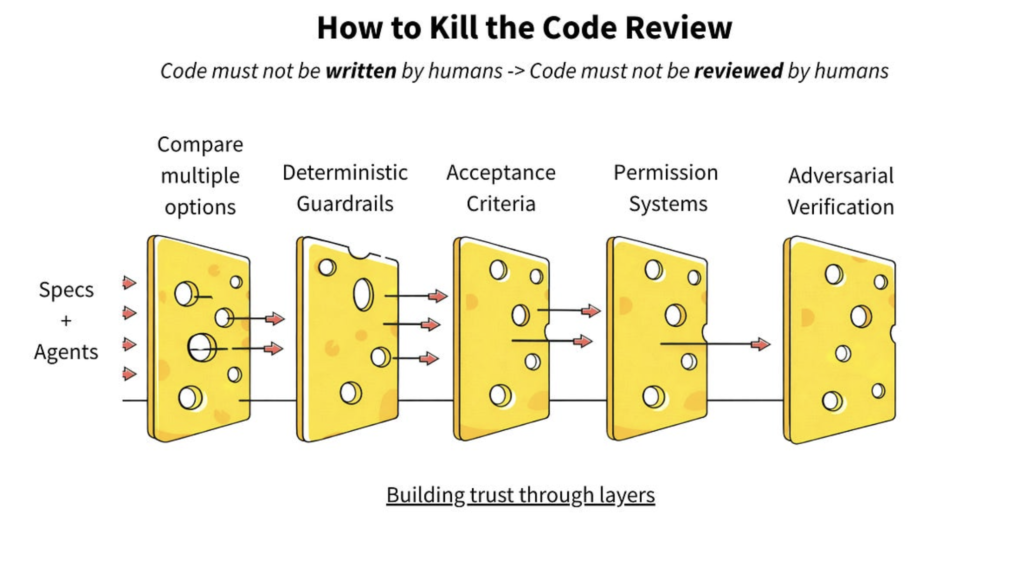
Five layers that replace traditional review
If we can’t read all the code and at the current pace of production, we can’t we need a layered system where no single hole causes a production outage. The Swiss cheese model: no filter is perfect, but stacked together they overlap so the holes stop lining up.
Layer 1: Comparing multiple options
Instead of asking one agent to „write it well”, ask three to write it differently and pick the best output. Let them compete. The cost of this optionality is today the lowest in the history of software engineering.
Selection doesn’t have to be manual. You can rank outputs by which diff is smallest, which passes the most tests, which introduces no new dependencies. Competition gives you a signal you won’t get from a single attempt.
Layer 2: Deterministic guardrails
This isn’t about opinions it’s about facts. Tests, type checking, contract verification. An agent doesn’t negotiate with a failing test. Either it meets the spec or it doesn’t.
Guardrails are worth arranging in a hierarchy:
- Coding guidelines – custom linters enforcing style and conventions
- Organizational invariants – absolute prohibitions, e.g. „no hardcoded credentials”
- Domain contracts – service-specific rules, e.g. „in the payments domain all amounts use the Money type”
- Acceptance criteria – task-specific criteria
Critical caveat: verification criteria must be created before the code, not after. If the agent writes both the code and its tests the problem is just displaced, not solved. Verification must come from the spec, not from the implementation.
A well-designed test automation pipeline is in this model the first and most important line of defense, not the last.
Layer 3: Humans define what success means
Behavior-Driven Development never caught on widely because writing specs before code felt like extra work. With agents the equation flips: the spec isn’t overhead it is the actual work.
A human writes: „a user with the admin role can delete an account, a user with the viewer role cannot”. The agent implements. The BDD framework verifies. Nobody needs to read the implementation unless something fails.
This is where human judgment is most valuable: defining what „correct” means, accounting for business logic, edge cases, and what could go wrong. The agent translates intent into code. The BDD spec becomes the verification layer deterministic, automated, and existing before the first line of code.
Layer 4: Permissions as architecture
What can this agent touch? What requires escalation? These are architectural decisions, not configuration options.
An agent fixing a bug in utils/dates.py doesn’t need access to the entire repository. It gets access to that file and its test. Scope should be as narrow as possible while remaining useful.
Escalation triggers matter equally: touching authorization logic, modifying the database schema, adding a new dependency these should automatically flag for human review, regardless of the agent’s confidence level.
Layer 5: Adversarial verification
One agent writes code. A second (who doesn’t know what the first did) tries to break it. They don’t trust each other. And that’s exactly the point.
This is an old pattern applied to new ground: QA shouldn’t report to the engineering manager, and the person who wrote the code shouldn’t be the only one who reviewed it. With agents you can enforce this architecturally the coding agent doesn’t know what the verification agent is looking for, and the verification agent can’t modify the code to make its job easier.
A third agent can actively hunt for edge cases and failure modes red team/blue team, automated, running on every change. In practice this is an extension of what QA testing services traditionally do, except it runs in a loop without human involvement at each iteration.
Reviewing AI-generated code: what’s worth keeping from the traditional approach
To be clear certain elements of classic review still make sense. Specifically the ones that can’t be automated.
Architectural decisions. Will this implementation be maintainable in a year? Does it introduce hidden dependencies that will become a problem at scale? An agent optimizes for the task. It doesn’t understand the history of decisions or the direction the system is heading. This is one of the reasons custom software development built on AI still requires senior architectural oversight. The tools have changed, but the responsibility hasn’t.
Business logic with nuance. Edge cases that don’t come from the code, but from domain knowledge. Things that technically work but are semantically wrong in the product context.
Security in critical places. Authorization logic, payment handling, personal data processing, human review makes sense here regardless of automated layers. Not because the agent will definitely make a mistake, but because the cost of a mistake is too high.
The difference is subtle but important: you’re not giving up human judgment, you’re moving it to where it’s irreplaceable.
Control questions for your team
If your team is actively using AI to write code, here’s a set of questions worth reviewing:
Where is your human checkpoint? Are you approving specs and acceptance criteria, or just skimming diffs? If it’s the latter, the checkpoint is in the wrong place.
Are your guardrails deterministic? Linter, tests, type checking, SAST- how many of them run automatically in CI/CD before any human looks at the code?
Who writes acceptance criteria? If the agent writes both the code and the tests you have a problem with the verification layer. Criteria must come from the spec, not from the implementation.
How narrow are your agents’ permissions? „Access to the whole repo” is not the right default answer.
What are you monitoring after deployment? Feature flags, instant rollback, observability this is the last safety layer. Speeding up without guardrails increases risk: AI-generated code is more volatile and more prone to serious issues without the right safeguards in place.
Summary
Reviewing AI-generated code isn’t going away we should, however, change what and when we review. Traditional line-by-line review loses its meaning at the scale AI generates. And spending senior attention on it is becoming simply irrational when a failing test can do the same job.
The fastest teams I know don’t trust AI more than others. They’ve built better safety nets and that’s why they can afford not to read every line. They save human judgment for things no model will grasp: architectural decisions, business logic with history, places where technically works isn’t enough.
The future is: ship fast, observe everything, revert faster.
Not: review slowly, miss bugs anyway, debug in production.


